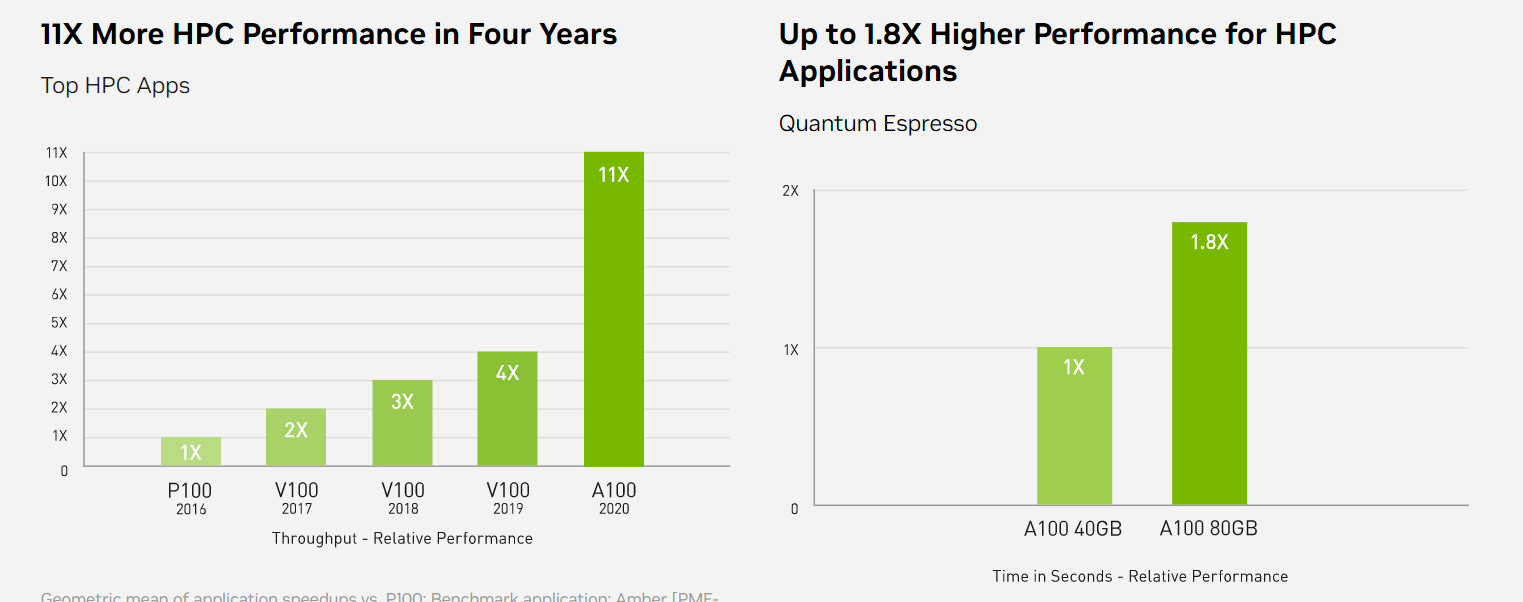Đánh Giá
Giới thiệu NVIDIA A100 Tensor Core GPU

21
Th3
Th3
NVIDIA A100 Tensor Core GPU là một card đồ họa công nghiệp mạnh được thiết kế để hỗ trợ các ứng dụng trí tuệ nhân tạo, phân tích dữ liệu và tính toán khoa học. Với kiến trúc Ampere của NVIDIA, A100 cung cấp hiệu năng vượt trội hơn 20 lần so với thế hệ trước đó và có thể phân vùng thành 7 GPU để tối ưu hóa hoạt động động linh hoạt. A100 80GB là phiên bản đầu tiên trên thế giới được trang bị băng thông bộ nhớ nhanh nhất hiện nay, lên đến 1.94TB/s. Với những tính năng và hiệu năng vượt trội, A100 được coi là một trong những card đồ họa công nghiệp mạnh mẽ nhất hiện nay. Trong bài này tôi sẽ giới thiệu về NVIDIA A100 Tensor Core GPU và các tính năng của nó.

 Các mô hình trí tuệ nhân tạo đang phát triển vượt bậc với độ phức tạp ngày càng tăng, đặc biệt là trong các thách thức cấp độ tiếp theo như trí tuệ nhân tạo hội thoại. Việc huấn luyện chúng đòi hỏi khả năng tính toán và khả năng mở rộng lớn.
GPU Tensor Core NVIDIA A100 với Tensor Float (TF32) cung cấp hiệu suất cao hơn tới 20 lần so với NVIDIA Volta mà không cần thay đổi mã và tăng thêm 2 lần nữa với tự động chính xác hỗn hợp và FP16. Khi kết hợp với NVIDIA NVLink, NVIDIA NVSwitch, PCI Gen4, NVIDIA InfiniBand và SDK NVIDIA Magnum IO, bạn có thể mở rộng tới hàng nghìn GPU A100.
Một công việc huấn luyện như BERT có thể được giải quyết với quy mô lớn trong thời gian dưới 1 phút bằng 2.048 GPU A100, một kỷ lục thế giới cho thời gian giải quyết.
Đối với các mô hình lớn với các bảng dữ liệu khổng lồ như các mô hình đề xuất học sâu (DLRM), A100 80GB đạt được lên đến 1,3 TB bộ nhớ thống nhất trên mỗi nút và cung cấp tăng thêm 3 lần số lượng thông qua so với A100 40GB.
MLPerf thiết lập nhiều kỷ lục về hiệu suất trong tiêu chuẩn đo lường rộng khắp ngành công nghiệp cho đào tạo trí tuệ nhân tạo (AI training)
Các mô hình trí tuệ nhân tạo đang phát triển vượt bậc với độ phức tạp ngày càng tăng, đặc biệt là trong các thách thức cấp độ tiếp theo như trí tuệ nhân tạo hội thoại. Việc huấn luyện chúng đòi hỏi khả năng tính toán và khả năng mở rộng lớn.
GPU Tensor Core NVIDIA A100 với Tensor Float (TF32) cung cấp hiệu suất cao hơn tới 20 lần so với NVIDIA Volta mà không cần thay đổi mã và tăng thêm 2 lần nữa với tự động chính xác hỗn hợp và FP16. Khi kết hợp với NVIDIA NVLink, NVIDIA NVSwitch, PCI Gen4, NVIDIA InfiniBand và SDK NVIDIA Magnum IO, bạn có thể mở rộng tới hàng nghìn GPU A100.
Một công việc huấn luyện như BERT có thể được giải quyết với quy mô lớn trong thời gian dưới 1 phút bằng 2.048 GPU A100, một kỷ lục thế giới cho thời gian giải quyết.
Đối với các mô hình lớn với các bảng dữ liệu khổng lồ như các mô hình đề xuất học sâu (DLRM), A100 80GB đạt được lên đến 1,3 TB bộ nhớ thống nhất trên mỗi nút và cung cấp tăng thêm 3 lần số lượng thông qua so với A100 40GB.
MLPerf thiết lập nhiều kỷ lục về hiệu suất trong tiêu chuẩn đo lường rộng khắp ngành công nghiệp cho đào tạo trí tuệ nhân tạo (AI training)


Tăng tốc công việc
NVIDIA A100 Tensor Core GPU cung cấp khả năng tăng tốc chưa từng có ở mọi quy mô để cung cấp năng lượng cho các trung tâm dữ liệu co giãn có hiệu suất cao nhất thế giới cho AI, phân tích dữ liệu và HPC. Được cung cấp bởi Kiến trúc NVIDIA Ampere, A100 là động cơ của nền tảng trung tâm dữ liệu NVIDIA. A100 cung cấp hiệu suất cao hơn đến 20 lần so với thế hệ trước và có thể được phân vùng thành bảy trường hợp sử dụng GPU để điều chỉnh động theo các yêu cầu thay đổi. Phiên bản A100 80GB ra mắt băng thông bộ nhớ nhanh nhất thế giới với hơn 2 terabyte trên giây (TB/s) để chạy các mô hình và tập dữ liệu lớn nhất.
Phần mềm phù hợp cho doanh nghiệp về AI
Nền tảng NVIDIA EGX bao gồm phần mềm tối ưu hóa cung cấp tính toán tăng tốc trên cơ sở hạ tầng. Với NVIDIA AI Enterprise, doanh nghiệp có thể truy cập bộ phần mềm AI và phân tích dữ liệu toàn diện dựa trên đám mây, được tối ưu hóa, được chứng nhận và được hỗ trợ bởi NVIDIA để chạy trên VMware vSphere với Hệ thống được chứng nhận bởi NVIDIA. NVIDIA AI Enterprise bao gồm các công nghệ cho phép từ NVIDIA để triển khai, quản lý và mở rộng các khối lượng công việc AI trong đám mây lai hiện đại.Nền tảng Trung tâm dữ liệu AI và HPC mạnh nhất
A100 là một phần của giải pháp trung tâm dữ liệu NVIDIA hoàn chỉnh bao gồm các khối xây dựng bao gồm phần cứng, mạng, phần mềm, thư viện và các mô hình và ứng dụng AI được tối ưu hóa từ NGC ™. Đại diện cho nền tảng AI và HPC từ đầu đến cuối mạnh nhất cho trung tâm dữ liệu, nó cho phép các nhà nghiên cứu nhanh chóng cung cấp kết quả thực tế và triển khai các giải pháp vào sản xuất với quy mô lớn.Deep Learning Training
 Các mô hình trí tuệ nhân tạo đang phát triển vượt bậc với độ phức tạp ngày càng tăng, đặc biệt là trong các thách thức cấp độ tiếp theo như trí tuệ nhân tạo hội thoại. Việc huấn luyện chúng đòi hỏi khả năng tính toán và khả năng mở rộng lớn.
GPU Tensor Core NVIDIA A100 với Tensor Float (TF32) cung cấp hiệu suất cao hơn tới 20 lần so với NVIDIA Volta mà không cần thay đổi mã và tăng thêm 2 lần nữa với tự động chính xác hỗn hợp và FP16. Khi kết hợp với NVIDIA NVLink, NVIDIA NVSwitch, PCI Gen4, NVIDIA InfiniBand và SDK NVIDIA Magnum IO, bạn có thể mở rộng tới hàng nghìn GPU A100.
Một công việc huấn luyện như BERT có thể được giải quyết với quy mô lớn trong thời gian dưới 1 phút bằng 2.048 GPU A100, một kỷ lục thế giới cho thời gian giải quyết.
Đối với các mô hình lớn với các bảng dữ liệu khổng lồ như các mô hình đề xuất học sâu (DLRM), A100 80GB đạt được lên đến 1,3 TB bộ nhớ thống nhất trên mỗi nút và cung cấp tăng thêm 3 lần số lượng thông qua so với A100 40GB.
MLPerf thiết lập nhiều kỷ lục về hiệu suất trong tiêu chuẩn đo lường rộng khắp ngành công nghiệp cho đào tạo trí tuệ nhân tạo (AI training)
Các mô hình trí tuệ nhân tạo đang phát triển vượt bậc với độ phức tạp ngày càng tăng, đặc biệt là trong các thách thức cấp độ tiếp theo như trí tuệ nhân tạo hội thoại. Việc huấn luyện chúng đòi hỏi khả năng tính toán và khả năng mở rộng lớn.
GPU Tensor Core NVIDIA A100 với Tensor Float (TF32) cung cấp hiệu suất cao hơn tới 20 lần so với NVIDIA Volta mà không cần thay đổi mã và tăng thêm 2 lần nữa với tự động chính xác hỗn hợp và FP16. Khi kết hợp với NVIDIA NVLink, NVIDIA NVSwitch, PCI Gen4, NVIDIA InfiniBand và SDK NVIDIA Magnum IO, bạn có thể mở rộng tới hàng nghìn GPU A100.
Một công việc huấn luyện như BERT có thể được giải quyết với quy mô lớn trong thời gian dưới 1 phút bằng 2.048 GPU A100, một kỷ lục thế giới cho thời gian giải quyết.
Đối với các mô hình lớn với các bảng dữ liệu khổng lồ như các mô hình đề xuất học sâu (DLRM), A100 80GB đạt được lên đến 1,3 TB bộ nhớ thống nhất trên mỗi nút và cung cấp tăng thêm 3 lần số lượng thông qua so với A100 40GB.
MLPerf thiết lập nhiều kỷ lục về hiệu suất trong tiêu chuẩn đo lường rộng khắp ngành công nghiệp cho đào tạo trí tuệ nhân tạo (AI training)
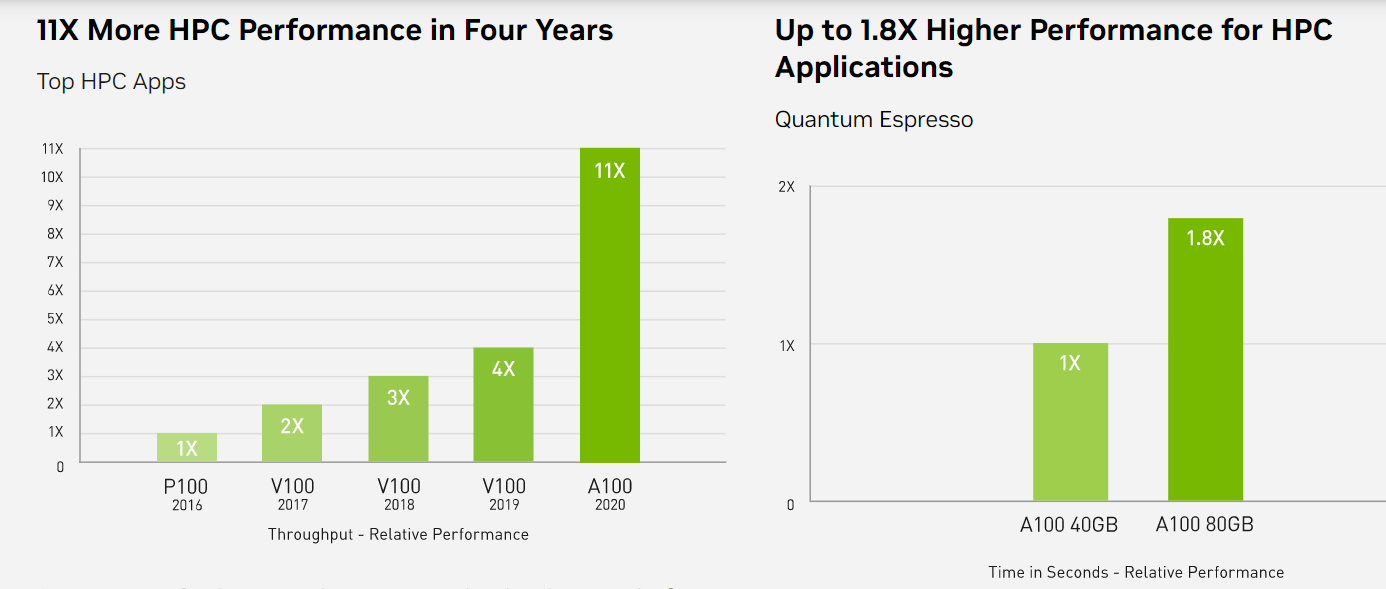
High-Performance Computing (HPC)
Để khám phá những phát hiện tiên tiến hơn, các nhà khoa học tìm đến các mô phỏng để hiểu hơn về thế giới xung quanh chúng ta. NVIDIA A100 giới thiệu double precision Tensor Cores để cung cấp bước nhảy vọt lớn nhất về hiệu suất HPC kể từ khi giới thiệu GPU. Kết hợp với 80GB bộ nhớ GPU nhanh nhất, các nhà nghiên cứu có thể giảm thời gian mô phỏng double-precision trong 10 giờ xuống dưới 4 giờ trên A100. Các ứng dụng HPC cũng có thể tận dụng TF32 để đạt được tốc độ xử lý cao hơn tới 11 lần cho các hoạt động dense matrix-multiply trong độ chính xác single-precision. Đối với các ứng dụng HPC có tập dữ liệu lớn nhất, bộ nhớ bổ sung 80GB của A100 mang lại tốc độ xử lý tăng gấp đôi với Quantum Espresso, một mô phỏng vật liệu. Bộ nhớ khổng lồ này và băng thông bộ nhớ chưa từng có giúp A100 80GB trở thành nền tảng lý tưởng cho các khối lượng công việc thế hệ tiếp theo.