

Đánh Giá
Đánh giá NVIDIA H100 Tensor Core GPU

29
Th3
Th3
NVIDIA H100 Tensor Core GPU là một sản phẩm mới nhất trong danh mục GPU của NVIDIA. H100 Tensor Core GPU có khả năng xử lý đồ họa tốt nhất trong lớp của nó, với 4096 nhân CUDA và 640 Tensor Core, cung cấp mức hiệu suất vượt trội cho các ứng dụng về AI và machine learning. Ngoài ra, NVIDIA H100 Tensor Core GPU còn được tích hợp với nhiều công nghệ mới nhất của NVIDIA, giúp nâng cao hiệu suất và khả năng tiết kiệm năng lượng, đồng thời cải thiện trải nghiệm người dùng. Theo chuyên gia đánh giá NVIDIA H100 Tensor Core GPU hứa hẹn sẽ là một lựa chọn hoàn hảo cho các doanh nghiệp và tổ chức muốn nâng cao khả năng tính toán của mình trong lĩnh vực AI và machine learning. Trong bài viết này mình sẽ đánh giá NVIDIA H100 Tensor Core GPU .







Mục lục
ẩn
Một bước nhảy vọt về tăng tốc tính toán của NVIDIA H100 Tensor Core GPU
Khám phá hiệu suất, tính mở rộng và bảo mật chưa từng có cho mọi tải trọng công việc với NVIDIA® H100 Tensor Core GPU. Với Hệ thống chuyển mạch NVIDIA NVLink®, tối đa 256 GPU H100 có thể được kết nối để tăng tốc tải trọng exascale. GPU này cũng bao gồm một Bộ chuyển đổi Transformer được dành riêng để giải quyết các mô hình ngôn ngữ với số lượng tham số lên tới nghìn tỷ. Những đổi mới công nghệ kết hợp của H100 có thể tăng tốc các mô hình ngôn ngữ lớn (LLMs) lên đến 30 lần so với thế hệ trước để cung cấp ứng dụng AI nói chuyện hàng đầu trong ngành.
Siêu tăng tốc khả năng suy luận của NVIDIA H100 Tensor Core GPU
Mô hình Ngôn ngữ Lớn Đối với các Mô hình Ngôn ngữ Lớn (LLMs) có đến 175 tỷ tham số, H100 NVL dựa trên giao tiếp PCIe với cầu NVLink sử dụng Bộ chuyển đổi Transformer, NVLink và bộ nhớ HBM3 188GB để cung cấp hiệu suất tối ưu và dễ dàng mở rộng trên bất kỳ trung tâm dữ liệu nào, đưa LLMs trở thành phổ biến. Các máy chủ được trang bị GPU H100 NVL tăng hiệu suất mô hình GPT-175B lên đến 12 lần so với hệ thống NVIDIA DGX™ A100 và vẫn giữ được độ trễ thấp trong môi trường trung tâm dữ liệu có hạn chế năng lượng.Sẵn sàng cho AI doanh nghiệp?
Sự áp dụng của AI trong doanh nghiệp hiện đã trở thành phổ biến, và các tổ chức cần cơ sở hạ tầng chuẩn bị sẵn AI từ đầu đến cuối sẽ giúp họ tăng tốc vào kỷ nguyên mới này. H100 cho máy chủ phổ thông đi kèm với một gói đăng ký năm năm, bao gồm hỗ trợ doanh nghiệp, cho bộ phần mềm NVIDIA AI Enterprise, đơn giản hóa việc áp dụng AI với hiệu suất tốt nhất. Điều này đảm bảo các tổ chức có quyền truy cập vào các khung công cụ và công cụ AI mà họ cần để xây dựng các luồng công việc AI tăng tốc H100 như chatbot AI, động cơ đề xuất, AI thị giác và nhiều hơn nữa.Huấn luyện AI
H100 có các Tensor Cores thế hệ thứ tư và một động cơ Transformer với độ chính xác FP8 cung cấp tốc độ huấn luyện lên đến 9 lần nhanh hơn so với thế hệ trước đối với các mô hình Mixture-of-experts (MoE). Sự kết hợp của NVLink thế hệ thứ tư, cung cấp 900 gigabyte mỗi giây (GB/s) kết nối giữa các GPU, hệ thống NVLink Switch tăng tốc giao tiếp cho mỗi GPU trên các node, PCIe Gen5 và phần mềm NVIDIA Magnum IO ™ mang lại tính mở rộng hiệu quả từ các hệ thống doanh nghiệp nhỏ đến các cụm GPU lớn, thống nhất. Triển khai H100 GPU trên quy mô trung tâm dữ liệu cung cấp hiệu suất đáng kinh ngạc và đưa thế hệ tiếp theo của tính toán hiệu năng cao exascale và AI với nghìn tỷ tham số trong tầm tay của tất cả các nhà nghiên cứu.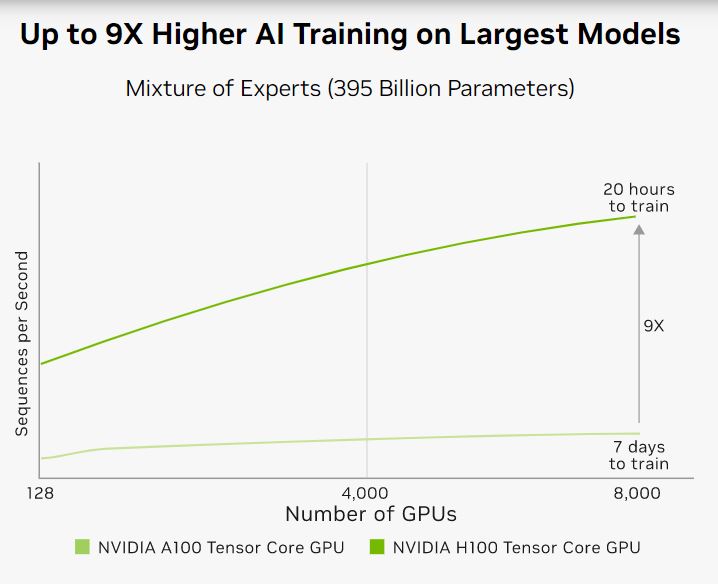
Real-Time Deep Learning Inference
Trí tuệ nhân tạo (AI) giải quyết một loạt các thách thức kinh doanh, sử dụng một loạt các mạng neural. Một trình tăng tốc AI phải không chỉ cung cấp hiệu suất cao nhất mà còn đa dạng để tăng tốc các mạng này. H100 mở rộng sự lãnh đạo về khả năng suy luận của NVIDIA với một số cải tiến giúp tăng tốc suy luận lên đến 30X và giảm thời gian trễ thấp nhất. Bốn thế hệ Tensor Cores tăng tốc cho tất cả các độ chính xác, bao gồm FP64, TF32, FP32, FP16, INT8 và hiện tại là FP8, để giảm sử dụng bộ nhớ và tăng hiệu suất trong khi vẫn đảm bảo độ chính xác cho LLMs.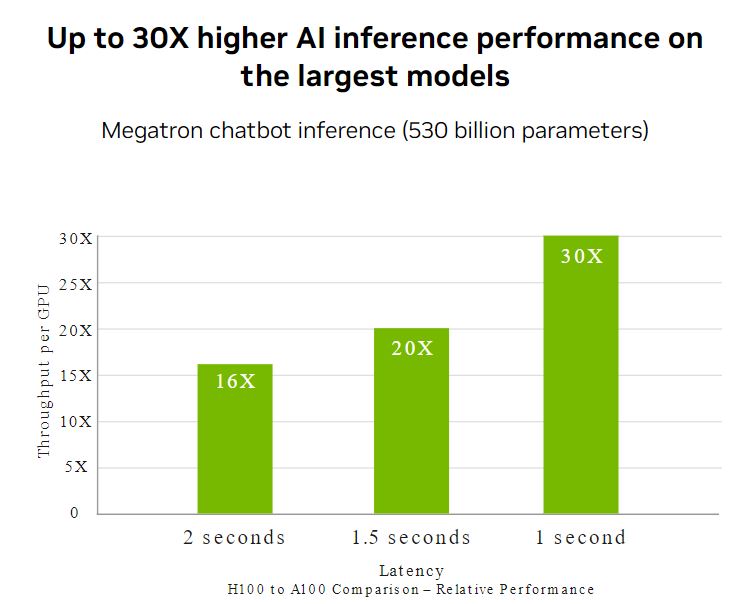
Exascale High-Performance Computing
Nền tảng trung tâm dữ liệu của NVIDIA liên tục mang lại những cải tiến hiệu suất vượt xa định luật Moore. Và các khả năng AI đột phá mới của H100 càng tăng cường sức mạnh của HPC + AI để giúp các nhà khoa học và nghiên cứu viên gia tăng tốc độ khám phá và giải quyết các thách thức quan trọng nhất của thế giới. Đánh giá NVIDIA H100 Tensor Core GPU tăng gấp ba lần số lần tính phép toán dấu chấm động (FLOPS) của Tensor Cores với độ chính xác đôi (FP64), cung cấp 60 teraflops tính toán FP64 cho HPC. Ứng dụng HPC kết hợp AI cũng có thể tận dụng độ chính xác TF32 của H100 để đạt được một petaflop của khối lượng xử lý cho các phép nhân ma trận đơn vị, mà không cần thay đổi mã nguồn. H100 cũng có các lệnh DPX mới cung cấp hiệu suất cao hơn 7 lần so với A100 và tăng tốc lên đến 40 lần so với CPU trên các thuật toán lập trình động như Smith-Waterman cho việc căn chỉnh chuỗi DNA và căn chỉnh protein cho dự đoán cấu trúc protein.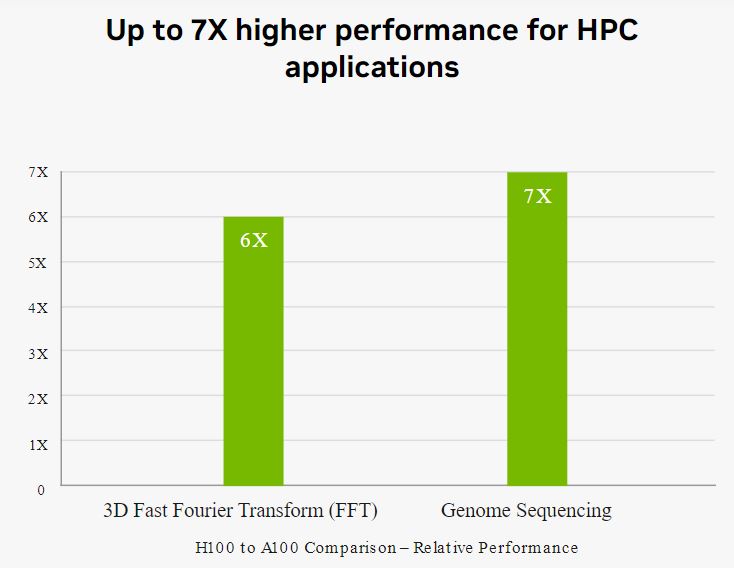
Accelerated Data Analytics
Trong quá trình phát triển ứng dụng trí tuệ nhân tạo, phân tích dữ liệu thường chiếm phần lớn thời gian. Vì các tập dữ liệu lớn được phân tán trên nhiều máy chủ, các giải pháp mở rộng với các máy chủ chỉ có CPU dễ bị giảm hiệu suất tính toán không mở rộng được. Các máy chủ được tăng tốc bằng H100 cung cấp sức mạnh tính toán – kèm theo băng thông bộ nhớ 3 terabytes mỗi giây (TB/s) cho mỗi GPU và khả năng mở rộng với NVLink và NVSwitch ™ – để xử lý phân tích dữ liệu với hiệu suất cao và khả năng mở rộng để hỗ trợ các tập dữ liệu khổng lồ. Kết hợp với NVIDIA Quantum-2 InfiniBand, phần mềm Magnum IO, Spark 3.0 được tăng tốc bằng GPU và NVIDIA RAPIDS ™, nền tảng trung tâm dữ liệu của NVIDIA có khả năng tăng tốc các khối lượng công việc khổng lồ này với mức độ hiệu suất và hiệu quả chưa từng có.
Enterprise-Ready Utilization
Những người quản lý công nghệ thông tin cố gắng tối đa hóa sử dụng tài nguyên tính toán trong trung tâm dữ liệu cả trong thời điểm cao điểm và trung bình. Họ thường sử dụng cấu hình tính toán động để định kích thước tài nguyên phù hợp cho các khối công việc đang được sử dụng. Công nghệ Multi-Instance GPU (MIG) thế hệ thứ hai trong H100 tối đa hóa việc sử dụng của mỗi GPU bằng cách phân chia chúng an toàn thành tối đa bảy trường hợp riêng biệt. Với hỗ trợ tính toán đáng tin cậy, H100 cho phép sử dụng đa người dùng an toàn, từ đầu đến cuối, làm cho nó lý tưởng cho môi trường cung cấp dịch vụ đám mây (CSP). H100 với MIG cho phép các quản lý cơ sở hạ tầng tiêu chuẩn hóa cơ sở hạ tầng tăng tốc GPU của họ trong khi vẫn có tính linh hoạt để cấp phát tài nguyên GPU với độ tinh giản lớn hơn để cung cấp đúng lượng tính toán tăng tốc cho nhà phát triển và tối ưu hóa việc sử dụng tất cả các tài nguyên GPU của họ.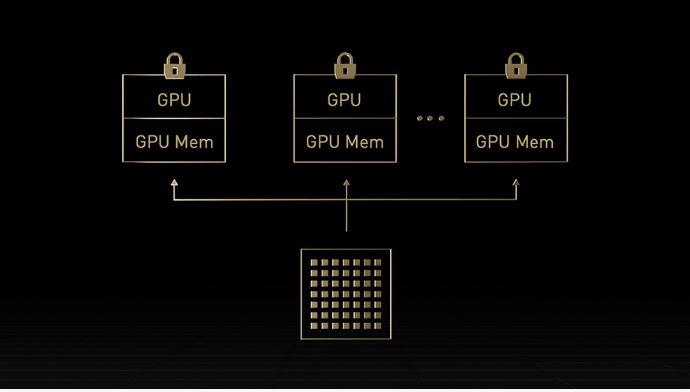
Hiệu suất cao cho AI và HPC quy mô lớn
GPU Tensor Core Hopper sẽ cung cấp sức mạnh cho kiến trúc CPU + GPU Grace Hopper của NVIDIA. Được thiết kế đặc biệt để tính toán gia tăng tỷ lệ terabyte và cung cấp hiệu suất cao hơn gấp 10 lần trên AI và HPC mô hình lớn. GPU Hopper được kết hợp với CPU Grace bằng cách sử dụng kết nối siêu nhanh chip-to-chip của NVIDIA. Và cung cấp băng thông 900GB/s, nhanh hơn 7 lần so với PCIe Gen5. Thiết kế sáng tạo này sẽ cung cấp tới 30 lần băng thông bộ nhớ hệ thống tổng thể cho GPU so với máy chủ nhanh nhất hiện nay và tăng hiệu suất lên đến 10 lần cho các ứng dụng chạy trên terabytes dữ liệu.
Thông số kỹ thuật sản phẩm
| Form Factor | H100 SXM | H100 PCIe | H100 NVL2 |
|---|---|---|---|
FP64 |
34 teraFLOPS | 26 teraFLOPS | 68 teraFLOPs |
FP64 Tensor Core |
67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
FP32 |
67 teraFLOPS | 51 teraFLOPS | 134 teraFLOPs |
TF32 Tensor Core |
989 teraFLOPS1 | 756teraFLOPS1 | 1,979 teraFLOPs1 |
BFLOAT16 Tensor Core |
1,979 teraFLOPS1 | 1,513 teraFLOPS1 | 3,958 teraFLOPs1 |
FP16 Tensor Core |
1,979 teraFLOPS1 | 1,513 teraFLOPS1 | 3,958 teraFLOPs1 |
FP8 Tensor Core |
3,958 teraFLOPS1 | 3,026 teraFLOPS1 | 7,916 teraFLOPs1 |
INT8 Tensor Core |
3,958 TOPS1 | 3,026 TOPS1 | 7,916 TOPS1 |
GPU memory |
80GB | 80GB | 188GB |
GPU memory bandwidth |
3.35TB/s | 2TB/s | 7.8TB/s |
Decoders |
7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 14 NVDEC 14 JPEG |
Max thermal design power (TDP) |
Up to 700W (configurable) | 300-350W (configurable) | 2x 350-400W (configurable) |
Multi-Instance GPUs |
Up to 7 MIGS @ 10GB each | Up to 14 MIGS @ 12GB each | |
Form factor |
SXM | PCIe dual-slot air-cooled | 2x PCIe dual-slot air-cooled |
Interconnect |
NVLink: 900GB/s PCIe Gen5: 128GB/s | NVLink: 600GB/s PCIe Gen5: 128GB/s | NVLink: 600GB/s PCIe Gen5: 128GB/s |
Server options |
NVIDIA HGX H100 Partner and NVIDIA-Certified Systems™ with 4 or 8 GPUs NVIDIA DGX H100 with 8 GPUs | Partner and NVIDIA-Certified Systems with 1–8 GPUs | Partner and NVIDIA-Certified Systems with 2-4 pairs |
NVIDIA AI Enterprise |
Add-on | Included | Add-on |